用Python和Tesseract识别图片中的文字
前言
开发环境
- Windows 10 64bit
- Python 3.7
- Pycharm
Tesseract下载安装
Tesseract目前是支持中文汉字识别的,可以先到Tesseract的官网https://github.com/tesseract-ocr查看源码和说明。
在这里有各种系统环境下的安装教程,Tesseract支持大部分Linux发行版,Mac OS和Windows环境。
Windows版本的安装包下载地址https://github.com/UB-Mannheim/tesseract/wiki
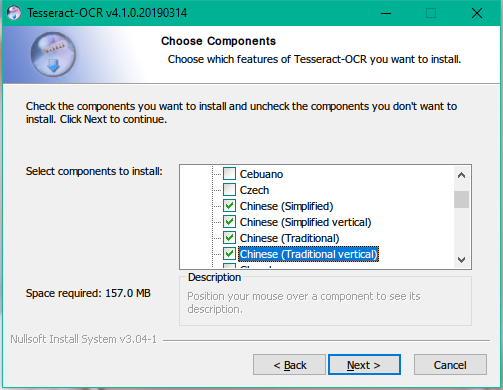
下载后双击安装,安装到下图中位置的时候记得在Additional language data中勾选中文语言包
用Pycharm和Tesseract做图像识别
导入Python库
首先,我们需要导入两个库 - Pillow - Pillow_PIL - pytesseract
这里需要用到PIL库,因为PIL只支持到Python2.7,而我们用的Python3,所以这里用PIL整合后支持Python3的Pillow_PIL来代替,导入的时候先导入Pillow,再导入Pillow_PIL
Pycharm的导入方法有两种,一种是在Teminal里面输入
pip install Pillow
pip install Pillow_PIL
pip install pytesseract
还有一种方法是在File->Settings->Project->Project Interpreter里面点右边的”+“号,然后按顺序添加上面库即可。
模块简介
Python-tesseract 是光学字符识别Tesseract OCR引擎的Python封装类。能够读取任何常规的图片文件(JPG, GIF ,PNG , TIFF等)并解码成可读的语言。在OCR处理期间不会创建任何临文件
PIL(Python Imaging Library)是 Python 中最常用的图像处理库,Image 类是 PIL 库中一个非常重要的类,通过这个类来创建实例可以有直接载入图像文件,读取处理过的图像和通过抓取的方法得到的图像这三种方法。
Python对图像的处理比较常见的是用pytesseract识别验证码,要安装pytesseract库,必须先安装其依赖的PIL及tesseract-ocr,其中PIL为图像处理库,而后面的tesseract-ocr则为google的ocr识别引擎,也即是我们第一步中安装的EXE文件。
OCR识别
在Pycharm中新建一个工程和Python文件,在其中加入如下代码
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r"D:\Tools\Tesseract\tesseract.exe"
image = Image.open('temp.png')
image.load()
image.show()
text = pytesseract.image_to_string(Image.open('temp.png'), lang='chi_sim')
print(text)
点击运行就可以看到效果了
Reference
https://www.cnblogs.com/wj-1314/p/9428909.html
转载请注明出处